показано, что более 70% отсканированных веб-сайтов были заражены одной или несколькими уязвимостями.
Как владелец веб-приложения, как вы гарантируете, что ваш сайт защищен от онлайн-угроз? Или от утечки конфиденциальной информации?
Если вы используете облачное решение для обеспечения безопасности, то, скорее всего, регулярное сканирование уязвимостей является частью плана защиты.
Однако, если нет, вам нужно выполнить рутинное сканирование и предпринять необходимые действия для смягчения рисков.
Существует два типа сканера.
1.Коммерческий — дает вам возможность автоматизировать сканирование для обеспечения непрерывной безопасности, отчетности, оповещений, подробных инструкций по смягчению рисков и т. д. Некоторые из известных имен в этой отрасли:
Acunetix
Detectify
Qualys
Open Source / Бесплатные — вы можете загружать и выполнять проверку безопасности по требованию.
Не все из них смогут охватить широкий спектр уязвимостей, таких как коммерческий.
Давайте посмотрим на следующие сканеры уязвимостей с открытым исходным кодом.
1. Arachni
Arachni — высокопроизводительный сканер безопасности, построенный на основе Ruby для современных веб-приложений.
Он доступен в двоичном формате для Mac, Windows и Linux.

Это не только решение для базового статического или веб-сайта с CMS, но также Arachni способен выполнять интеграцию со следующиим платформами.
Он выполняет активные и пассивные проверки.
Windows, Solaris, Linux, BSD, Unix
Nginx, Apache, Tomcat, IIS, Jetty
Java, Ruby, Python, ASP, PHP
Django, Rails, CherryPy, CakePHP, ASP.NET MVC, Symfony
Некоторые из обнаруженных уязвимостей:
NoSQL / Blind / SQL / Code / LDAP / Command / XPath injection
Подделка запросов межсайтовый скриптинг
Обход пути
Включение локального / удаленного файла
Разделение ответа
Межсайтовый скриптинг
Неопределенные перенаправления DOM
Раскрытие исходного кода
2. XssPy
Сканер уязвимостей XSS (межсайтовый скриптинг) на основе python используется многими организациями, включая Microsoft, Stanford, Motorola, Informatica и т.д.
XssPy by Faizan Ahmad — умный инструмент. Вместо того, чтобы просто проверять домашнюю страницу или страницу, она проверяет всю ссылку на веб-сайтах.
XssPy также проверяет субдомен.
3. w3af
w3af, проект с открытым исходным кодом, начатый еще в конце 2006 года, основан на Python и доступен для Linux и ОС Windows. w3af способен обнаруживать более 200 уязвимостей, включая OWASP top 10.
Он поддерживает различные методы ведения журнала для отчетности. Пример:
CSV
HTML
Консоль
Текст
XML
Эл. адрес
Он построен на архитектуре плагина, и вы можете проверить все доступные плагины.
4. Nikto
Проект с открытым исходным кодом, спонсируемый Netsparker, направлен на поиск неправильной конфигурации веб-сервера, плагинов и уязвимостей в Интернете.
5. Wfuzz
Wfuzz (Web Fuzzer) — это инструмент оценки приложений для тестирования на проникновение.
Вы можете заглушить данные в HTTP-запросе для любого поля, чтобы использовать веб-приложение и проверять его.
Wfuzz требует наличия Python на компьютере, на котором вы хотите запустить сканирование.
6. OWASP ZAP
ZAP (Zet Attack Proxy) — один из известных инструментов тестирования на проникновение, который активно обновляется сотнями добровольцев во всем мире.
Это кросс-платформенный Java-инструмент, который может работать даже на Raspberry Pi.
ZIP находится между браузером и веб-приложением для перехвата и проверки сообщений.
Некоторым из следующих функций ZAP, которые следует упомянуть.
Fuzzer
Автоматический и пассивный сканер
Поддержка нескольких языков сценариев
Принудительный просмотр
7. Wapiti
Wapiti просматривает веб-страницы заданной цели и ищет сценарии и форму для ввода данных, чтобы узнать, является ли оно уязвимым.
Это не проверка безопасности исходного кода, а скорее проверка блэк боксов.

Он поддерживает методы GET и POST HTTP, прокси HTTP и HTTPS, несколько аутентификаций и т. д.
8. Vega
Vega разработан Subgraph, многоплатформенное программное обеспечение, написанное на Java, для поиска XSS, SQLi, RFI и многих других уязвимостей.
Vega получил удобный графический интерфейс и способен выполнять автоматическое сканирование, войдя в приложение с заданными учетными данными.

Если вы разработчик, вы можете использовать vega API для создания новых модулей атаки.
9. SQLmap
Как вы можете догадаться по имени, с помощью вы можете выполнить тестирование проникновения в базу данных, чтобы найти недостатки.
Он работает с Python 2.6 или 2.7 на любой ОС. Если вы хотите , то sqlmap будет полезен как никогда.
10. Grabber
Это небольшой инструмент, основанный на Python, делает несколько вещей достаточно хорошо.
Некоторые из функций Grabber:
Анализатор исходного кода JavaScript
Межсайтовый скриптинг, SQL-инъекция, слепое внедрение SQL
Тестирование PHP-приложений с использованием PHP-SAT
11. Golismero
Фреймворк для управления и запуска некоторых популярных инструментов безопасности, таких как Wfuzz, DNS recon, sqlmap, OpenVas, анализатор роботов и т. д.).

Golismero может консолидировать отзывы от других инструментов и показать один результат.
12. OWASP Xenotix XSS
Xenotix XSS OWASP — это расширенная инфраструктура для поиска и использования межсайтовых скриптов.
Он имеет встроенные три интеллектуальных фьюзера для быстрого сканирования и улучшения результатов.
13. Metascan
Сканер по поиску уязвимостей веб-приложений от отечественных разработчиков
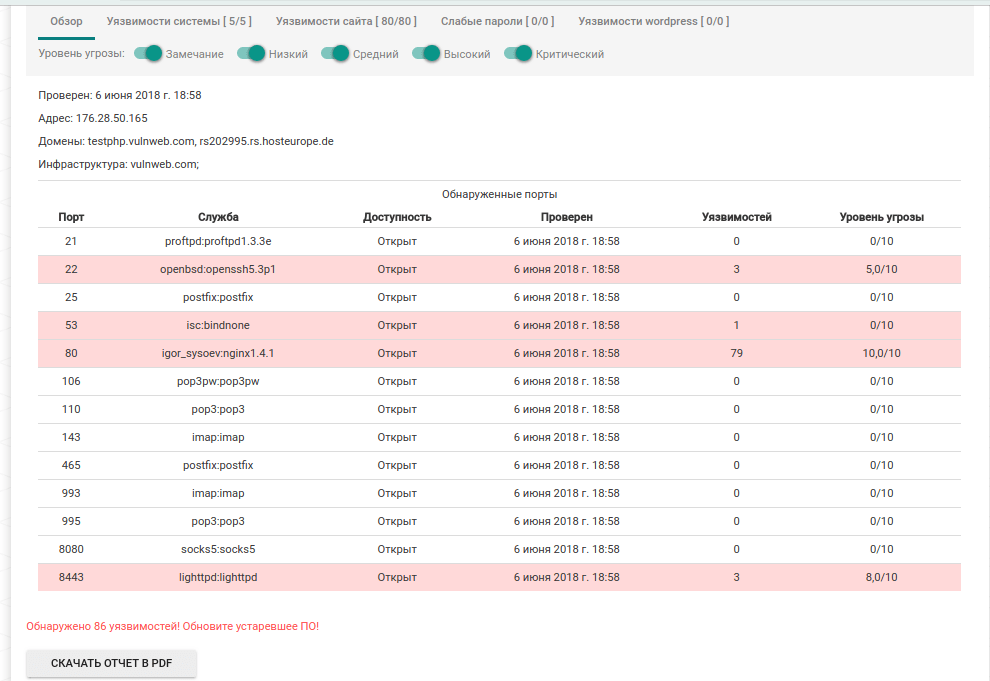
1. Цель и задачи
Целью работы является разработка алгоритмов повышения безопасности доступа к внешним информационным ресурсам из корпоративных образовательных сетей с учетом характерных для них угроз безопасности, а также особенностей контингента пользователей, политик безопасности, архитектурных решений, ресурсного обеспечения.
Исходя из поставленной цели, в работе решаются следующие задачи:
1. Выполнить анализ основных угроз информационной безопасности в образовательных сетях.
2. Разработать метод ограничения доступа к нежелательным информационным ресурсам в образовательных сетях.
3. Разработать алгоритмы, позволяющие осуществлять сканирование веб-страниц, поиск прямых соединений и загрузку файлов для дальнейшего анализа потенциально вредоносного кода на сайтах.
4. Разработать алгоритм идентификации нежелательных информационных ресурсов на сайтах.
2. Актуальность темы
Современные интеллектуальные обучающие системы являются Web-ориентированными и предусматривают для своих пользователей возможность работы с различными видами локальных и удаленных образовательных ресурсов. Проблема безопасного использования информационных ресурсов (ИР), размещенных в сети Интернет, постоянно приобретает все большую актуальность . Одним из методов, используемых при решении данной проблемы, является ограничение доступа к нежелательным информационным ресурсам.
Операторы, предоставляющие доступ в Интернет образовательным учреждениям, обязаны обеспечить ограничение доступа к нежелательным ИР. Ограничение осуществляется путем фильтрации операторами по спискам, регулярно обновляемым в установленном порядке. Однако, учитывая назначение и пользовательскую аудиторию образовательных сетей, целесообразно использовать более гибкую, самообучающуюся систему, которая позволит динамически распознавать нежелательные ресурсы и ограждать от них пользователей.
В целом доступ к нежелательным ресурсам несет следующие угрозы: пропаганду противоправных и асоциальных действий, таких как: политический экстремизм, терроризм, наркомания, распространение порнографии и других материалов; отвлечение учащихся от использования компьютерных сетей в образовательных целях; затруднение доступа в Интернет из-за перегрузки внешних каналов, имеющих ограниченную пропускную способность. Перечисленные выше ресурсы часто используются для внедрения вредоносных программ с сопутствующими им угрозами .
Существующие системы ограничения доступа к сетевым ресурсам имеют возможность проверять на соответствие заданным ограничениям не только отдельные пакеты, но и их содержимое - контент, передаваемый через сеть. В настоящее время в системах контентной фильтрации применяются следующие методы фильтрации web-контента: по имени DNS или конкретному IP-адресу, по ключевым словам внутри web-контента и по типу файла. Чтобы блокировать доступ к определенному web-узлу или группе узлов, необходимо задать множество URL, контент которых является нежелательным. URL-фильтрация обеспечивает тщательный контроль безопасности сети. Однако нельзя предугадать заранее все возможные неприемлемые URL-адреса. Кроме того, некоторые web-узлы с сомнительным информационным наполнением работают не с URL, а исключительно с IP-адресами.
Один из путей решения задачи состоит в фильтрации контента, получаемого по протоколу HTTP. Недостатком существующих систем контентной фильтрации является использование списков разграничения доступа, формируемых статически. Для их наполнения разработчики коммерческих систем контентной фильтрации нанимают сотрудников, которые делят контент на категории и составляют рейтинг записей в базе данных .
Для устранения недостатков существующих систем фильтрации контента для образовательных сетей актуальна разработка систем фильтрации web-трафика с динамическим определением категории web-ресурса по содержимому его страниц.
3. Предполагаемая научная новизна
Алгоритм ограничения доступа пользователей интеллектуальных обучающих систем к нежелательным ресурсам Интернет-сайтов, основанный на динамическом формировании списков доступа к информационным ресурсам путем их отложенной классификации.
4. Планируемые практические результаты
Разработанные алгоритмы могут использоваться в системах ограничения доступа к нежелетельным ресурсам в интеллектуальных системах компьютерного обучения.
5. Обзор исследований и разработок
5.1 Обзор исследований и разработок по теме на глобальном уровне
Проблемам обеспечения информационной безопасности посвящены работы таких известных ученых как: H.H. Безруков, П.Д. Зегжда, A.M. Ивашко, А.И. Костогрызов, В.И. Курбатов К. Лендвер, Д. Маклин, A.A. Молдовян, H.A. Молдовян, А.А.Малюк, Е.А.Дербин, Р. Сандху, Дж. М. Кэррол, и других. Вместе с тем, несмотря на подавляющий объем текстовых источников в корпоративных и открытых сетях, в области разработки методов и систем защиты информации в настоящее время недостаточно представлены исследования, направленные на анализ угроз безопасности и исследование ограничения доступа к нежелательным ресурсам при компьютерном обучении с возможностями доступа к Web.
В Украине ведущим исследователем в данной сфере является Домарев В.В. . Его диссертационные исследования посвящены проблемам создания комплексных систем защиты информации. Автор книг: «Безопасность информационных технологий. Методология создания систем защиты», «Безопасность информационных технологий. Системный подход» и др., автор более 40 научных статей и публикаций.
5.2 Обзор исследований и разработок по теме на национальном уровне
В Донецком национальном техническом университете разработкой моделей и методов для создания системы информационной безопасности корпоративной сети предприятия с учетом различных критериев занималась Химка С.С. . Защитой информации в обучающих системах Заняла Ю.С. .
6. Проблемы ограничения доступа к веб-ресурсам в образовательных системах
Развитие информационных технологий в настоящее время позволяет говорить о двух аспектах описания ресурсов Интернет-контент и инфраструктура доступа. Под инфраструктурой доступа принято понимать множество аппаратных и программных средств, обеспечивающих передачу данных в формате IP-пакетов, а контент определяется как совокупность формы представления (например, в виде последовательности символов в определенной кодировке) и контента (семантики) информации. Среди характерных свойств такого описания следует выделить следующие:
1. независимость контента от инфраструктуры доступа;
2. непрерывное качественное и количественное изменение контента;
3. появление новых интерактивных информационных ресурсов («живые журналы», социальные сети, свободные энциклопедии и др.), в которых пользователи непосредственно участвуют в создании сетевого контента.
При решении задач управления доступом к информационным ресурсам большое значение имеют вопросы выработки политики безопасности, которые решаются по отношению к характеристикам инфраструктуры и сетевого контента. Чем выше уровень описания модели информационной безопасности, тем в большей степени управление доступом ориентировано на семантику сетевых ресурсов. Очевидно, что MAC и IP-адреса (канальный и сетевой уровень взаимодействия) интерфейсов сетевых устройств невозможно привязать к какой-либо категории данных, так как один и тот же адрес может представлять различные сервисы. Номера портов (транспортный уровень), как правило, дают представление о типе сервиса, но качественно никак не характеризуют информацию, предоставляемую этим сервисом. Например, невозможно отнести определенный Web-сайт к одной из семантических категорий (СМИ, бизнес, развлечения и т.д.) только на основании информации транспортного уровня. Обеспечение информационной защиты на прикладном уровне вплотную приближается к понятию контентной фильтрации, т.е. управления доступом с учетом семантики сетевых ресурсов. Следовательно, чем более ориентирована на контент система управления доступом, тем более дифференцированный подход по отношению к различным категориям пользователей и информационных ресурсов можно реализовать с ее помощью. В частности, семантически ориентированная система управления способна эффективно ограничить доступ учащихся образовательных учреждений к ресурсам, не совместимым с процессом обучения.
Возможные варианты процесса получения веб-ресурса представлены на рис.1
Рисунок 1 - Процесс получения веб-ресурса по протоколу HTTP
Чтобы обеспечить гибкий контроль использования Интернет-ресурсов, необходимо ввести в компании-операторе соответствующую политику использования ресурсов образовательной организацией. Эта политика может реализовываться как «вручную», так и автоматически. «Ручная» реализация означает, что в компании имеется специальный штат сотрудников, которые в режиме реального времени или по журналам маршрутизаторов, прокси-серверов или межсетевых экранов ведут мониторинг активности пользователей образовательного учреждения. Такой мониторинг является проблематичным, поскольку требует больших трудозатрат. Чтобы обеспечить гибкий контроль использования Интернет ресурсов, компания должна дать администратору инструмент для реализации политики использования ресурсов организацией. Этой цели служит контентная фильтрация. Ее суть заключается в декомпозиции объектов информационного обмена на компоненты, анализе содержимого этих компонентов, определении соответствия их параметров принятой политике использования Интернет-ресурсов и осуществлении определенных действий по результатам такого анализа. В случае фильтрации веб трафика под объектами информационного обмена подразумеваются веб-запросы, содержимое веб страниц, передаваемые по запросу пользователя файлы.
Пользователи учебной организации получают доступ к сети Интернет исключительно через proxy-сервер. При каждой попытке получения доступа к тому либо иному ресурсу proxy-сервер проверяет - не внесен ли ресурс в специальную базу. В случае если такой ресурс размещен в базе запрещенных - доступ к нему блокируется, а пользователю выдается на экран соответствующее сообщение.
В случае, если запрошенный ресурс отсутствует в базе запрещённых ресурсов то доступ к нему предоставляется, однако запись о посещении данного ресурса фиксируется в специальном служебном журнале. Один раз в день (или с другим периодом) proxy-сервер формирует перечень наиболее посещаемых ресурсов (в виде списка URL) и отправляет его экспертам. Эксперты (администраторы системы) с использованием соответствующей методики проверяют полученный перечень ресурсов и определяет их характер. В случае, если ресурс имеет нецелевой характер, эксперт осуществляет его классификацию (порноресурс, игровой ресурс) и вносит изменение в базу данных. После внесения всех необходимых изменений обновлённая редакция базы данных автоматически пересылается всем proxy-серверам, подключённым к системе. Схема фильтрации нецелевых ресурсов на proxy-серверах приведена на рис. 2.

Рисунок 2 - Базовые принципы фильтрации нецелевых ресурсов на proxy-серверах
Проблемы фильтрации нецелевых ресурсов на proxy-серверах следующие. При централизованной фильтрации необходима высокая производительность оборудования центрального узла, большая пропускная способность каналов связи на центральном узле, выход из строя центрального узла ведет к полному выходу из строя всей системы фильтрации.
При децентрализованной фильтрации «на местах» непосредственно на рабочих станциях или серверах организации большая стоимость разворачивания и поддержки.
При фильтрации по адресу на этапе отправки запроса отсутствует превентивная реакция на наличие нежелательного контента, сложности при фильтрации «маскирующихся» веб-сайтов.
При фильтрации по контенту необходима обработка больших объёмов информации при получении каждого ресурса, сложность обработки ресурсов подготовленных с использованием таких средств как Java, Flash.
7. Информационная безопасность веб-ресурсов для пользователей интеллектуальных обучающих систем
Рассмотрим возможность управления доступом к ИР при помощи распространенного решения, основанного на иерархическом принципе комплексирования средств управления доступом к ресурсам Интернет (рис.3). Ограничение доступа к нежелательным ИР из ИОС может быть обеспечено путем сочетания таких технологий как межсетевое экранирование, использование прокси-серверов, анализ аномальной деятельности с целью обнаружение вторжений, ограничение полосы пропускания, фильтрация на основе анализа содержания (контента), фильтрация на основании списков доступа. При этом одной из ключевых задач является формирование и использование актуальных списков ограничения доступа.
Фильтрация нежелательных ресурсов проводится в соответствии с действующими нормативными документами на основании публикуемых в установленном порядке списков. Ограничение доступа к иным информационным ресурсам производится на основании специальных критериев, разрабатываемых оператором образовательной сети.
Доступ пользователей с частотой, ниже заданной даже к потенциально нежелательному ресурсу, является допустимым. Анализу и классификации подлежат только востребованные ресурсы, то есть те, для которых число запросов пользователей превысило заданное пороговое значение. Сканирование и анализ осуществляются спустя некоторое время после превышения числа запросов порогового значения (в период минимальной загрузки внешних каналов).
Сканируются не единичные веб-страницы, а все связанные с ними ресурсы (путем анализа имеющихся на странице ссылок). В результате данный подход позволяет в процессе сканирования ресурса определять наличие ссылок на вредоносные программы.

Рисунок 3 -Иерархия средств управления доступом к ресурсам Интернет
(анимация, 24 кадра, 25 Кб)
Автоматизированная классификация ресурсов производится на корпоративном сервере клиента - владельца системы. Время классификации определяется используемым методом, в основе которого лежит понятие отложенной классификации ресурса. При этом предполагается, что доступ пользователей с частотой ниже заданной даже к потенциально нежелательному ресурсу является допустимым. Это позволяет избежать дорогостоящей классификации «на лету». Анализу и автоматизированной классификации подлежат только востребованные ресурсы, то есть ресурсы, частота запросов пользователей к которым превысила заданное пороговое значение. Сканирование и анализ осуществляются спустя некоторое время после превышения числа запросов порогового значения (в период минимальной загрузки внешних каналов). Метод реализует схему динамического построения трех списков: «черного»(ЧСП), «белого»(БСП) и «серого»(ССП). Ресурсы, находящиеся в «черном» списке запрещены для доступа. «Белый» список содержит проверенные разрешенные ресурсы. «Серый» список содержит ресурсы, которые хотя бы один раз были востребованы пользователями, но не прошли классификацию. Первоначальное формирование и дальнейшая «ручная» корректировка «черного» списка производится на основании официальной информации об адресах запрещенных ресурсов, предоставляемых уполномоченным государственным органом. Первоначальное содержание «белого» списка составляют рекомендованные для использования ресурсы. Любой запрос ресурса, не относящегося к «черному» списку, удовлетворяется. В том случае, если этот ресурс не находится в «белом» списке, он помещается в «серый» список, где фиксируется количество запросов к этому ресурсу. Если частота запросов превышает некоторое пороговое значение, проводится автоматизированная классификация ресурса, на основании чего он попадает в «черный» или «белый» список.
8. Алгоритмы определения информационной безопасности веб-ресурсов для пользователей интеллектуальных обучающих систем
Алгоритм ограничения доступа. Ограничения доступа к нежелательным ресурсам Интернет-сайтов основывается на следующем определении понятия риска доступа к нежелательному ИР в ИОС. Риском доступа к нежелательному i-му ИР, отнесенному к к-му классу ИР, будем называть величину, пропорциональную экспертной оценке ущерба, наносимого нежелательным ИР данного вида ИОС или личности пользователя и числу обращений к данному ресурсу за заданный отрезок времени:
![]()
По аналогии с классическим определением риска как произведения вероятности реализации угрозы на стоимость наносимого ущерба, данное определение трактует риск как математическое ожидание величины возможного ущерба от доступа к нежелательному ИР. При этом величина ожидаемого ущерба определяется степенью воздействия ИР на личности пользователей, которая в свою очередь прямо пропорциональна числу пользователей, испытавших это воздействие.
В процессе анализа любого веб-ресурса, с точки зрения желательности или нежелательности доступа к нему, необходимо рассматривать следующие основные компоненты каждой его страницы: контент, то есть текстовую и иную (графическую, фото, видео) информацию, размещенную на этой странице; контент, размещенный на других страницах этого же веб-сайта (получить внутренние ссылки из содержимого загруженных страниц можно по регулярным выражениям); соединения с другими сайтами (как с точки зрения возможной загрузки вирусов и троянских программ), так и с точки зрения наличия нежелательного контента. Алгоритм ограничения доступа к нежелательным ресурсам с использованием списков приведен на рис. 4.

Рисунок 4 -Алгоритм ограничения доступа к нежелательным ресурсам
Алгоритм определения нежелательных Web-страниц. Для классификации контента - текстов веб-страниц - необходимо решить следующие задачи: задание категорий классификации; извлечение из исходных текстов информации, поддающейся автоматическому анализу; создание коллекций проклассифицированных текстов; построение и обучение классификатора, работающего с полученными наборами данных.
Обучающее множество проклассифицированных текстов подвергают анализу, выделяя термы - наиболее часто употребляемые словоформы в целом и по каждой категории классификации в отдельности. Каждый исходный текст представляют в виде вектора, компонентами которого являются характеристики встречаемости данного терма в тексте. Для того чтобы избежать разреженности векторов и уменьшить их размерность, словоформы целесообразно привести к начальной форме методами морфологического анализа. После этого вектор следует нормализовать, что позволяет добиться более корректного результата классификации. Для одной веб-страницы можно сформировать два вектора: для информации, отображаемой для пользователя, и для текста, предоставляемого поисковым машинам.
Известны различные подходы к построению классификаторов веб-страниц. Наиболее часто используемыми являются : байесовский классификатор; нейронные сети; линейные классификаторы; метод опорных векторов (SVM). Все вышеназванные методы требуют обучения на обучающей коллекции и проверки на тестирующей коллекции. Для бинарной классификации можно выбрать наивное байесовское решение, предполагающее независимость друг от друга характеристик в векторном пространстве. Будем считать, что все ресурсы необходимо классифицировать как желательные и нежелательные. Тогда вся коллекция образцов текстов веб-страниц разделяется на два класса: C={C1, C2} причем априорная вероятность каждого класса P(Ci), i=1,2. При достаточно большой коллекции образцов можно считать, что P(Ci) равняется отношению количества образцов класса Ci к общему количеству образцов. Для некоторого подлежащего классификации образца D из условной вероятности P(D/Ci), согласно теореме Байеса, может быть получена величина P(Ci /D):

с учетом постоянства P(D) получаем:

Предполагая независимость друг от друга термов в векторном пространстве, можно получить следующее соотношение:
Для того чтобы более точно классифицировать тексты, характеристики которых близки (например, различать порнографию и художественную литературу, в которой описываются эротические сцены), следует ввести весовые коэффициенты:

Если kn=k; если kn меньше k, kn.=1/|k|. Здесь M - частота всех термов в базе данных образцов, L - количество всех образцов.
9. Направления совершенствования алгоритмов
В дальнейшем предполагается разработать алгоритм анализа ссылок с целью выявления внедрения вредоносного кода в код web-страницы и сравнить байесовский классификатор с методом опорных векторов.
10. Выводы
Выполнен анализ проблемы ограничения доступа к веб-ресурсам в образовательных системах. Выбраны базовые принципы фильтрации нецелевых ресурсов на proxy-серверах на основе формирования и использование актуальных списков ограничения доступа. Разработан алгоритм ограничения доступа к нежелательным ресурсам с использованием списков, позволяющий динамически формировать и обновлять списки доступа к ИР на основе анализа их контента с учетом частоты посещений и контингента пользователей. Для выявления нежелательного контента разработан алгоритм на основе наивного байесовского классификатора.
Список источников
- Зима В. М. Безопасность глобальных сетевых технологий / В. Зима, А. Молдовян, Н. Молдовян. - 2-е изд. - СПб.: БХВ-Петербург, 2003. - 362 c.
- Воротницкий Ю. И. Защита от доступа к нежелательным внешним информационным ресурсам в научно-образовательных компьютерных сетях / Ю. И. Воротницкий, Се Цзиньбао // Мат. XIV Межд. конф. «Комплексная защита информации». - Могилев, 2009. - С. 70-71.
Сайт – как сад: чем больше в него вложено труда, тем щедрее плоды. Но бывает и такое, когда политый, удобренный и заботливо обихоженный сайт вдруг с треском вылетает из поисковой выдачи. Что это? Происки конкурентов? Обычно причина гораздо банальнее — на вашем веб-ресурсе завелись вирусы.
Итак, откуда берутся вирусы на сайтах, по каким симптомам их определить, как проверить любимое детище на присутствие вредоносного ПО и как защитить его от всей этой нечисти.
Источники, признаки и цели вирусного заражения интернет-ресурсов
Путей проникновения вирусов на веб-сайты намного меньше, чем, например, на устройства. Точнее, их всего 3:
- Зараженный компьютер, с которого на сайт загружаются файлы. На этот фактор приходится более 90% случаев.
- Взлом. Он может быть целевым, например, если вас «заказали» конкуренты по бизнесу или ресурс чем-то привлек внимание злоумышленников, и случайным — потому что плохо закрыто.
- Уязвимости CMS, серверных систем, плагинов и другого ПО, с которым соприкасаются сайты.
Как вирусы проявляют свое присутствие:
- Резко и необоснованно уменьшается количество посетителей. Веб-ресурс сильно теряет позиции или выпадает из выдачи поисковых систем. При попытке открыть его в браузере вместо страниц появляются грозные предупреждения, вроде такого:
- Самопроизвольно меняется дизайн страниц. Появляются «левые» рекламные баннеры, блоки, ссылки и контент, который вы не размещали. Если на ресурсе производятся денежные расчеты, могут измениться платежные реквизиты.
- Нарушается функциональность сайта, по ссылкам открывается не то, что должно.
- Посетители жалуются, что на ваш сайт ругаются антивирусы или после его открытия на их устройствах появились признаки заражения.
В чем заключается вредоносная деятельность вирусов на интернет-ресурсах:
- В воровстве контента, баз данных, трафика, денег.
- В заражении устройств посетителей и других уязвимых сайтов на том же сервере.
- В перенаправлении ваших посетителей на нужные злоумышленникам ресурсы, например, путем установки дорвеев со спам-ссылками или добавления вредоносного кода мобильного редиректа в.htaccess. Этот код перенаправляет на другие сайты только тех, кто зашел с мобильных устройств.
- В повышении чьих-то поисковых позиций за ваш счет.
- В рассылке с вашей почты спама и вредоносных сообщений. Часто с целью внесения вашего email в почтовые базы злостных спамеров, чтобы ваши подписчики и пользователи не получали от вас писем.
- В полном или частичном выводе веб-ресурса из строя, а также в намеренном удалении его из поисковой индексации (клоакинг).
- В установке на сервер web-shell’ов и бэкдоров, с помощью которых злоумышленник получает удаленный доступ к файловой системе сервера.
Способы диагностики безопасности сайта
Проверить сайт на вирусы можно несколькими способами. Самый быстрый и простой, но довольно поверхностный вариант — проверка при помощи антивирусных онлайн-сканеров. С нее стоит начинать всегда, когда есть хоть малейшее подозрение на присутствие зловреда.
Если проверка сайта онлайн выявила угрозу, следом желательно провести полное пофайловое сканирование при помощи антивирусных программ.
Кроме того, некоторые веб-мастера практикуют ручной метод поиска вирусов — открытие и просмотр каждого подозрительного файла на наличие закладок. Поиск проводится по сигнатурам (фрагментам кода, который часто встречается во вредоносных объектах) и путем сравнения потенциально зараженных файлов с чистыми. Если есть знания и опыт, этот метод может быть наиболее надежным, ведь угрозы пропускают даже самые мощные и рейтинговые антивирусы.
Проблемы с безопасностью на сайтах часто первыми замечают поисковые системы:
- Яндекс.Вебмастер отображает информацию о них на странице «Диагностика» — «Безопасность и нарушения».

- Google Search Console — в разделе «Инструменты для вебмастеров» — «Состояние» — «Вредоносные программы».

В случае обнаружения зловредного ПО выполните рекомендации Яндекс и Google по его поиску и устранению. А следом проверьте сайт при помощи онлайн-сканеров.
Онлайн-сканеры для проверки сайтов на вирусы и взлом
i2p
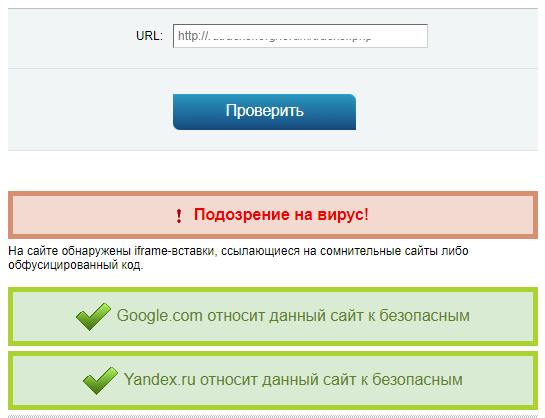
i2p — простой бесплатный русскоязычный сервис для быстрой проверки веб-ресурсов — целиком или отдельных страниц, на вредоносное содержимое. Анализ занимает несколько секунд, но результат, увы, не всегда оказывается достоверным. «Подозрения на вирус», как в примере ниже, могут быть вполне безобидны. Просто они требуют более пристального внимания.
— один из самых известных и популярных антивирусных сканеров онлайн. Проверяет интернет-ресурсы (а также любые файлы) движками 65 антивирусов, включая Касперского, Dr.Web, ESET, Avast, BitDefender, Avira и т. д. Отображает репутацию проверенного сайта по данным голосования сообщества Virustotal. Интерфейс сервиса только на английском языке.
Чтобы провести проверку веб-ресурса на Вирустотал, откройте на главной странице вкладку URL, вставьте ссылку в поле «Search or scan URL» и нажмите на иконку лупы.
Сервис не просто сообщает о чистоте или заражении веб-сайта, а выводит список проверенных файлов с пометками о том, что вызвало подозрение. Анализ основывается на собственных и мировых антивирусных базах.
Другие разделы сервиса наполнены статьями о диагностике, самостоятельном ручном удалении вирусов, защите от заражения, резервном копировании и прочими материалами о безопасности Интернет-ресуров.
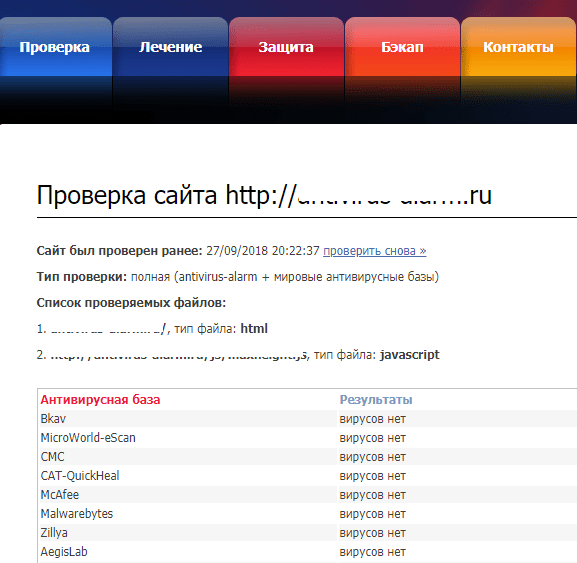
Лаборатория Dr Web анализирует состояние веб-сайтов, используя только собственные базы и алгоритмы.
По результатам сканирования формируется отчет:
- Обнаружено ли на объекте зловредное ПО.
- Находится ли он в чьих-нибудь базах вредоносных объектов.
- Перенаправляет ли он посетителей на другие ресурсы.
Ниже отображаются результаты проверки файлов и дополнительные сведения о подозрительных фактах.
Xseo
Неприглядный на вид веб-сервис Xseo на самом деле информативнее и функциональнее многих. Он проверяет сайты на наличие шести с лишним миллионов известных вирусов, на предмет фишинга, а также выводит оценку их безопасности по версиям MyWOT, Яндекс и Google. Кроме того, Xseo содержит массу других полезных и бесплатных SEO-инструментов. Доступ к некоторым из них требует регистрации.

— еще один бесплатный сервис проверки безопасности интернет-ресурсов. Способен выявлять признаки заражения известным вредоносным ПО, находить на сайтах ошибки, «пробивать» их по базам черных списков и определять актуальность версии CMS. Интерфейс сервиса на английском, испанском и португальском языках.
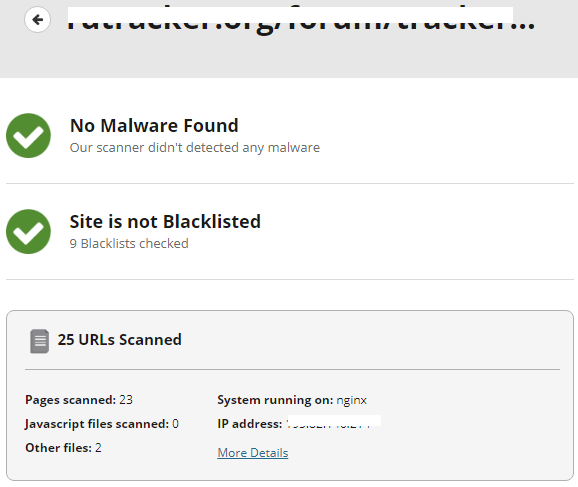
— инструмент комплексной проверки интернет-ресурсов на заражение и взлом. Выявляет следующие виды угроз:
- Зашифрованные скрипты.
- Скрытые редиректы.
- Шпионские закладки, вставки и виджеты с подозрительных сайтов.
- Атаки Drive-by (загрузка вредоносной программы без ведома пользователя).
- Спамные ссылки и контент.
- Ошибки и признаки дефейса.
- Внесение в блэклисты поисковиков и антивирусов.
После бесплатного сканирования «не отходя от кассы» предлагает заказать услуги лечения вирусов и защиты сайта у своих специалистов. Уже платно.
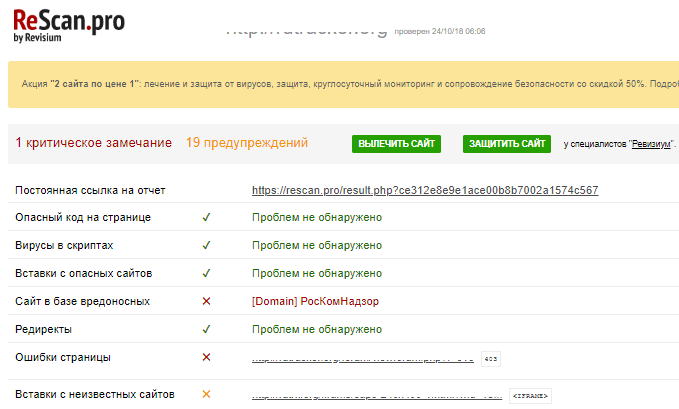
Проверяет репутацию ссылок — значится ли ресурс в списке зараженных или фишинговых по базам Kaspersky Security Network.
Сканер ищет вредоносное ПО как по базам, так и на основе эвристического анализа, благодаря чему иногда обнаруживает угрозы, о которых еще не знают антивирусы. Помимо сканирования, сервис предлагает платные услуги очистки сайтов от вирусов и последующую профилактику заражения.
Интерфейс Quttera на английском языке.

Русскоязычный сервис проверяет сайты при помощи 20 различных антивирусов. В дополнение к этому предлагает платные услуги очистки от найденных зловредов и установки постоянных средств защиты.
Проверка сайта при помощи антивируса на компьютере
Следующий этап проверки веб-ресурса на безопасность — сканирование всех его файлов антивирусной программой, установленной на ПК. Для этой задачи подойдет любой комплексный a\v продукт со свежими базами. Можете использовать тот, которому больше доверяете.
Перед сканированием вам предстоит скачать содержимое сайта в отдельную папку на ПК либо на съемный носитель, а далее, не трогая содержимое папки, запустить проверку. Не стоит кликать по файлам, иначе вредоносное ПО может заразить ваш компьютер.
В случае обнаружения угроз лучше и быстрее всего заменить зараженные файлы чистыми, взяв последние из резервных копий. Если копий нет, удалить опасные объекты можно и вручную, но перед этим обязательно сделайте бэкап.
Что может быть потенциально опасным:
- Встроенные фреймы и скрипты (можно найти по словам iframe и javascript).
- Подгружаемые скрипты.
- Редиректы на сторонние ресурсы (даже нормальные и незараженные).
- Подгружаемые картинки и другие мультимедийные объекты.
- Прочие внешние дополнения.
- Файлы с датой изменения, которая близка к предполагаемой дате заражения.
Удалять всё подряд, конечно, не следует, сначала эти объекты необходимо изучить. Если самостоятельный анализ вызывает затруднения, лучше доверить его специалистам.
После очистки обязательно смените пароли, которые использовались для доступа к сайту и аккаунту на хостинге.
Как защитить сайт от вирусов
Как уже сказано, основная масса случаев попадания на веб-ресурсы вредоносного ПО — следствие заражения компьютера, через который администратор управляет сайтом. Поэтому:
- Следите за «здоровьем» компьютера: ограничьте доступ к нему членам семьи, откажитесь от непроверенных программ, не кликайте по неизвестным ссылкам, время от времени проводите полное антивирусное сканирование и т. д.
- Не доверяйте хранение паролей от сайта, баз и аккаунта на хостинге браузерам и FTP/SSH-клиентам. Используйте защищенный . Сами пароли должны быть длинными и сложными. Не забывайте периодически их менять.
- Старайтесь заходить на сайт только по SFTP или SSH, протокол FTP небезопасен.
- Не удаляйте логи ошибок и доступов к сайту раньше, чем они могли бы вам пригодиться.
- Своевременно обновляйте CMS, дополнительные модули и плагины. Если эти объекты были скомпрометированы или перестали поддерживаться, они уязвимы для зловредов и хакерских атак. Замените их на более безопасные аналоги. Также откажитесь от использования ПО из непроверенных источников.
- Установите на сайт хороший антивирус, например, скрипт очистки от вирусов и следов взлома AI-Bolit, или подключите его к сервису автоматического лечения и защиты, вроде Virusdie.
Подробнее о сервисах AI-Bolit и Virusdie
AI-Bolit (Айболит) — легкий, нетребовательный к ресурсам антивирусный скрипт, предназначенный для поиска всех видов вредоносного ПО и уязвимостей на хостинге и сайтах. Поддерживает любые операционные системы, скрипты и СМS. Для личного некоммерческого использования базовые функции сервиса доступны бесплатно. В случае заражения специалисты помогают с анализом отчетов, лечением и установкой превентивной защиты.
Virusdie — сервис комплексной антивирусной поддержки (антивирус, файервол, проводник и редактор файлов). Помимо автоматического поиска и удаления вирусов, помогает снять с сайта блокировки и прочие санкции хостинг-провайдеров, антивирусного ПО и поисковых систем. Поддерживает большинство популярных СМS. Услуги сервиса платные, защита одного сайта стоит 249-1499 рублей в год.
Чистого вам Интернета!
Рисунок 2. Внешний вид веб-приложения Mutillidae
Методика тестирования
Теперь, когда мы подготовили тестовый стенд, можно рассмотреть процесс тестирования, который будет представлять собой следующую последовательность действий:
- Подготовка тестового приложения к сканированию
- Настройка сканера безопасности
- Запуск процесса сканирования с выбранными настройками
- Анализ результатов и занесение их в таблицу
| Тип уязвимости | Найдено | Ложно найдено | Время |
|---|---|---|---|
Таблица 1. Результаты сканирования
После того как будут проведены все серии тестирования для всех сканеров, мы занесем полученные результаты в сводную таблицу.
|
The Path Traversal / Local File Inclusion |
Sensitive Data Exposure |
Затраченное время |
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
Ложно обнару- |
Ложно обнару-жено |
Ложно обнару- |
Ложно обнару- |
Ложно обнару- |
|||||||
Таблица 2. Итоговая таблица результатов
В процессе проведения тестов мы столкнемся с несколькими проблемами:
- Сканеры безопасности отличаются своей настройкой и функционалом. Для того чтобы отразить в нашем тестировании специфические особенности сканеров, мы будем проводить по несколько серий сканирования с различными конфигурациями настроек для получения более качественного результата (если это возможно).
- Сканеры безопасности бывают специализированы на определенном типе уязвимости либо могут определять широкий спектр уязвимостей. Если сканер специализирован на определенном типе уязвимости, следовательно, он должен более качественно определять их, в противном случае мы будем акцентирование особое внимания на не идентифицированной или ложно идентифицированной уязвимости специализированным сканером.
- Типы уязвимостей. Так как существует большое множество типов уязвимостей, нам надо определиться с теми типами, которые мы будем отражать в итоговом отчете. В данном вопросе мы будем руководствоваться классификацией OWASP Top 10 2013 и выберем из этого списка пять типов уязвимостей.
- Количество уязвимостей в веб-приложении. Заранее знать о том, какое количество уязвимостей содержится в тестовом Web приложении, мы не можем, поэтому за общее число мы возьмем сумму найденных уязвимостей всеми сканерами.
Настройка сканеров и начало тестирования
SkipFish
Данный сканер представляет собой полностью автоматизированный инструмент с консольным интерфейсом и обладает небольшим количеством настроек, с полным перечнем которых можно ознакомиться с помощью команды skipfish -h. Для запуска процесса сканирования автор предлагает три базовых варианта:
- skipfish -W /dev/null -LV […other options…] – в данном режиме запуска сканер выполняет упорядоченный обход цели и в принципе работает также как другие сканеры. Не рекомендуется вследствие ограниченного охвата ресурсов цели, но зато процесс сканирования занимает значительно меньше времени по сравнению с остальными режимами;
- skipfish -W dictionary.wl -Y […other options…] – в данном режиме сканер использует фаззинг только имен файлов или расширений. Этот режим предпочтителен, если есть ограничение по времени и при этом требуется получить приемлемый результат;
- skipfish -W dictionary.wl […other options…] – в данном режиме сканер перебирает все возможные пары имя и расширение. Этот режим значительно медленнее предыдущих, но при этом он проводит более детальный анализ веб-приложения. Разработчик сканера рекомендует использовать данный вариант по умолчанию.
Skipfish -W dictionary.wl -o ~/report/ http://target/
W – указываем путь к словарю, который мы будем использовать;
O – указываем директорию, в которую будем сохранять отчет.
| Тип уязвимости | Найдено | Ложно найдено | Время |
|---|---|---|---|
| SQL injection | 6 | 5 | 3ч18м |
| XSS | 11 | 2 | |
| CSRF | 1 | 1 | |
| 3 | 2 | ||
| Sensitive Data Exposure | 128 | 0 |
Таблица 3. Результаты сканирования SkipFish
Рисунок 3. Окончание процесса сканирования SkipFish
SkipFish неплохо справился с поставленной задачей, несмотря на большое количество ложных срабатываний. Стоит заметить, что хоть сканер и не имеет графического интерфейса, он очень прост в настройке. Также помимо результатов, отраженных в таблице, SkipFish обнаружил много интересной информации о Web-приложение, проанализировав которую можно улучшить защищенность приложения
SQLMap
Основной целью данного сканера является автоматический поиск и эксплуатация SQL уязвимостей. Он обладает огромным количеством настроек, позволяющих оптимизировать процесс поиска и эксплуатации уязвимостей. Для запуска сканирования можно воспользоваться визардом: sqlmap —wizard или простейшей командой: sqlmap -u «http://www.target.com/vuln.php?id=1». Мы же постараемся полностью автоматизировать процесс поиска и максимизировать результат. Запускать процесс сканирования мы будем двумя способами:
Sqlmap –u "http://target/" -o –v 4 --crawl=4 --level=3 --risk=2 --forms --batch --dbms=mysql sqlmap –l ~/burplog.log -o –v 4 --batch --level=3 --risk=2 --dbms=mysql
В первом способе мы используем встроенный в SQLMap краулер, а во втором – файл логов Burp Suite. А теперь прокомментируем параметры, которые мы использовали:
U – после данного параметра указываем адрес цели сканирования;
L – после данного параметра указываем путь к файлу с логами Burp Suite (или WebScarab);
O – включаем оптимизацию;
V – устанавливаем уровень подробности выводимой информации;
—dbms – устанавливаем СУБД, которую использует наша цель;
—forms – включаем парсинг и анализ форм, содержащихся в тестовом приложении;
—crawl – включаем встроенный краулер, который будет сканировать нашу цель;
—batch – так как мы решили полностью автоматизировать процесс поиска и эксплуатации, мы воспользуемся этим параметром, он заставляет SQLMap выполнять все действия по умолчанию, а не запрашивать решение у пользователя;
—level, —risk – увеличиваем количество используемых тестов, при этом значительно увеличивается время сканирования.
| Тип уязвимости | Найдено | Ложно найдено | Время |
|---|---|---|---|
| SQL injection | 14 | 0 | 4ч27м |
| XSS | - | - | |
| CSRF | - | - | |
| The Path Traversal / Local File Inclusion | - | - | |
| Sensitive Data Exposure | - | - |
Таблица 4. Результаты сканирования SQLMap
Рисунок 4. Эксплуатация обнаруженной SQL уязвимости
Как мы писали выше, SQLMap является специализированным инструментов для поиска и эксплуатации SQL уязвимостей, он справился с этой задачей на отлично, хотя полная автоматизация не дала такого результата. Добиться такого результата нам удалось благодаря ручному анализу. Стоит отметить, что время тестирования достаточно продолжительное, учитывая то, что мы занимались поиском только одного типа уязвимостей. Настройка данного сканера без подробного ознакомления с богатым перечнем опций является наиболее сложной из всех представленных в этой статье сканеров.
Acunetix Web Vulnerability Scanner (Acunetix WVS)
Данный инструмент является единственным платным представителем, работающим только на платформе Windows, в нашем тестировании. Сканер имеет как графический, так и консольный интерфейс. Для запуска процесса сканирования нужно воспользоваться визардом, в котором будет предложено использовать как стандартные настройки, так и специально сконфигурированные.
Итак, приступим к настройке сканера:
- На первом шаге нам предлагают ввести адрес цели, либо выбрать файл со структурой сайта, который был получен с помощью инструмента «Site Crawler», мы выберем первый вариант
- На втором шаге нам предстоит выбрать профиль сканирования, их достаточно много, мы выберем профиль «Default», так как он содержит в себе тесты для поиска всех доступных типов уязвимостей и настройки сканирования, которые мы оставим дефолтными
- На третьем шаге сканер пытается определить технологии, которые использует цель, и отображает полученные значения, при этом их можно выбрать самому либо выставить значение «Unknown». В нашем случае все значения были определены верно, и мы их оставим без изменения
- Следующим шагом предлагается выбрать способ аутентификации, так как нам она не потребуется, мы пропустим этот шаг
- На последнем шаге предлагается сохранить настройки и после нажатия «Finish» начинается процесс сканирования
| Тип уязвимости | Найдено | Ложно найдено | Время |
|---|---|---|---|
| SQL injection | 1 | 0 | 2ч 13м |
| XSS | 31 | 0 | |
| CSRF | 19 | 0 | |
| The Path Traversal / Local File Inclusion | 4 | 3 | |
| Sensitive Data Exposure | 231 | 0 |
Таблица 5. Результаты сканирования Acunetix WVS
Рисунок 5. Окончание процесса сканирования Acunetix WVS
Простота настройки и минимум ложных срабатываний вот — что можно сказать про данный инструмент. Помимо результатов, занесенных в таблицу, Acunetix WVS собрал много информации, касающейся структуры веб-приложения и конфиденциальных данных пользователей. Одной из полезных фич сканера можно выделить предоставление подробной информации об уязвимости и методах её устранения, а также ссылки на ресурсы, содержащие исчерпывающую информацию.
Web Application Attack and Audit Framework (w3af)
Фреймворк с графическим и консольным интерфейсом, позволяющий искать и эксплуатировать уязвимости в веб-приложении. Благодаря широкому спектру плагинов можно достаточно тонко настроить процесс сканирования. Также в w3af есть готовые шаблоны для сканирования, пользователю надо ввести только адрес цели.
При настройке сканера мы будем базироваться на шаблонах «full_audit» и «full_audit_spider_man», их отличие заключается в том, что в первом шаблоне в качестве плагина краулера используется web_spider – классический web-паук, а во втором spider_man – локальный прокси. Для наших целей нам не понадобятся плагины из группы «bruteforce», включенные по умолчанию в выбранных шаблонах, поэтому мы их выключим. Осталось настроить плагины из группы «output». По умолчанию вывод собранной информации производится только в консоль, что для анализа результатов не очень удобно, поэтому мы включим плагин «html_file», который позволяет сохранять всю полученную информацию в HTML-файл.
Теперь можно ввести адрес цели и начать сканирование.
| Тип уязвимости | Найдено | Ложно найдено | Время |
|---|---|---|---|
| SQL injection | 4 | 2 | 2ч57м |
| XSS | 3 | 1 | |
| CSRF | 25 | 0 | |
| The Path Traversal / Local File Inclusion | 4 | 3 | |
| Sensitive Data Exposure | 17 | 0 |
Таблица 6. Результаты сканирования w3af
Рисунок 6. Детали запроса, содержащего SQL уязвимость
Не зря данный инструмент является фреймворком, при определенных навыках настройки он способен собрать исчерпывающую информацию о цели за приемлемое время. Но и он не лишен недостатков, в процессе тестирования мы столкнулись с проблемой стабильности работы сканера, что не могло не огорчить.
Итоги тестирования
Что же показало наше тестирование? Если у вас появились задачи, связанные с проведением аудита безопасности веб-приложения, вам следует запастись терпением и временем. В таблице, представленной ниже можно обратить внимание на время, которое занял процесс сканирования каждым из инструментов. Оно не очень большое, причина в следующем: во-первых, тестовое приложение и сканеры безопасности находились на одной физической машине и, во-вторых, данное время не включает в себя процесс анализа полученных результатов, в реальных условиях время тестирования будет занимать значительно больше времени. Как вы успели заметить, результаты, предоставленные сканерами различаются: какой-то сканер лучше справился с поиском той или иной уязвимости, какой-то предоставил более подробную информацию о приложении в целом. В связи с этим при аудите безопасности не стоит полагаться только на один инструмент, надо использовать комплекс различных средств, в том числе и ручной анализ веб-приложения. Также стоит сказать, что веб-технологии развиваются со стремительной скоростью, и сканеры безопасности не поспевают за их развитием, поэтому перед проведением аудита надо подробно ознакомиться с технологиями, используемыми в тестируемом веб-приложении, чтобы более точно подобрать комплекс инструментов и методик.
|
SQL injection | ||
|---|---|---|
Лучших веб-сервисов, с помощью которых можно исследовать сайты на уязвимости. По оценке HP , 80% всех уязвимостей вызвано неправильными настройками веб-сервера, использованием устаревшего ПО либо другими проблемами, которых можно было легко избежать.
Сервисы из обзора помогают определить такие ситуации. Обычно сканеры осуществляют проверку по базе известных уязвимостей. Некоторые из них довольно просты и только проверяют открытые порты, а другие работают тщательнее и даже пытаются осуществить SQL-инъекцию.
WebSAINT
SAINT - известный сканер уязвимостей, на основе которого сделаны веб-сервисы WebSAINT и WebSAINT Pro . Как Approved Scanning Vendor, сервис осуществляет ASV-сканирование сайтов организаций, для которых это необходимо по условиями сертификации PCI DSS. Может работать по расписанию и проводить периодические проверки, составляет различные отчеты по результатам сканирования. WebSAINT сканирует порты TCP и UDP на указанных адресах в сети пользователя. В «профессиональной» версии добавлены пентесты и сканирование веб-приложений и настраиваемые отчеты.
ImmuniWeb

Сервис ImmuniWeb от компании High-Tech Bridge использует немного другой подход к сканированию: кроме автоматического сканирования, здесь предлагают еще пентесты вручную. Процедура начинается в указанное клиентом время и занимает до 12 часов. Отчет просматривают сотрудники компании перед тем, как отправить клиенту. В нем указывают как минимум три способа устранения каждой выявленной уязвимости, в том числе варианты изменения исходного кода веб-приложения, изменение правил файрвола, установка патча.
За человеческий труд приходится платить больше, чем за автоматическую проверку. Полное сканирование с пентестами ImmuniWeb стоит $639.

BeyondSaaS
BeyondSaaS от BeyondTrust обойдется еще дороже. Клиентам предлагают оформить подписку за $3500, после чего они могут проводить неограниченное количество проверок в течение года. Однократный скан стоит $700. Сайты проверяются на SQL-инъекции, XSS, CSRF и уязвимости операционной системы. Разработчики заявляют вероятность ложных срабатываний не более 1%, а в отчетах тоже указывают варианты исправления проблем.
Компания BeyondTrust предлагает и другие инструменты для сканирования на уязвимости, в том числе бесплатный Retina Network Community, который ограничен 256 IP-адресами.
Dell Secure Works

Dell Secure Works , возможно, самый продвинутый из веб-сканеров, представленных в обзоре. Он работает на технологии QualysGuard Vulnerability Management и проверяет веб-серверы, сетевые устройства, серверы приложений и СУБД как внутри корпоративной сети, так и на облачном хостинге. Веб-сервис соответствует требованиям PCI, HIPAA, GLBA и NERC CIP.





